這篇文章會整理這一個月來整合 Edge TTS 功能到 EinkBro 中的過程。經過一連串的開發後,總算是把自己想要的功能都開發出來了。
為什麼要整合?
目前 Android 手機上的 Accessibility Service 常常在更新,它的文字轉語音效果也比前幾年有明顯的進步。但是,聽起來還是感覺得出來比較機器人一點。目前能通吃所有語言的 OpenAI tts 文字轉語音,雖然什麼語言的文字丟給它它都可以唸得出來,但是 ABC 的腔調還是聽起來不是很舒服。所以,開始著手找看看是不是有機會將其他的語音轉文字整合到 EinkBro 中。
找方案
其他比較大間可以選擇的,再來應該就是微軟的文字轉語音方案,它的語音效果相當好,朗讀文字內容時很自然。目前微軟推出的 Edge 瀏覽器中可以免費使用此服務;如果有商用需求,或是超出其免費使用量的話,可以也採用微軟推出的 Azure AI Speech 來提供服務。
和 Android 內建的語音轉文字功能不同的是:它無法下載資料檔離線使用。在使用時,必須透過打 API 的方式,取得語音的音檔,再利用設備上的多媒體播放函式庫進行播放。
在 Android 上比較有名的整合實作是 tts-server-android。下面是它在 github 上的介紹:
- 这是一个Android系统TTS应用,内置微软演示接口,可自定义HTTP请求,可导入其他本地TTS引擎,以及根据中文双引号的简单旁白/对话识别朗读 ,还有自动重试,备用配置,文本替换等更多功能。
- 内置微软接口(Edge大声朗读、Azure演示API(已猝) ),可自定义HTTP请求,可导入其他本地TTS引擎,以及根据中文双引号的简单旁白/对话识别朗读 ,还有自动重试,备用配置,文本替换等更多功能。
其設定介面如下 (有點複雜…)
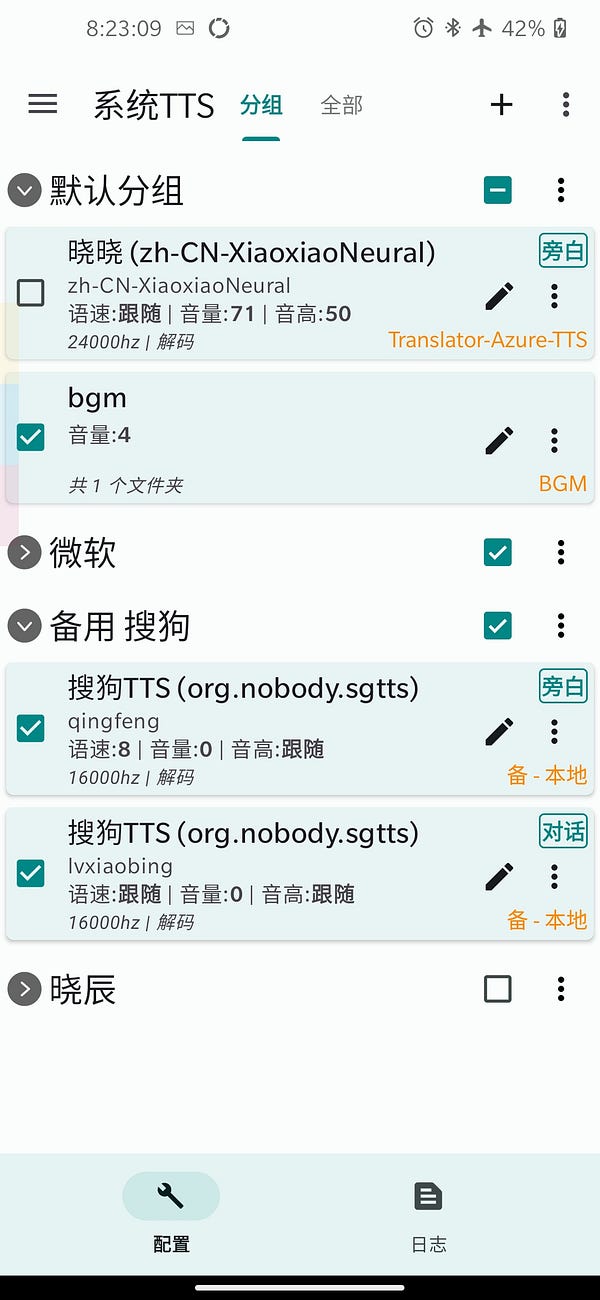
我曾嘗試著安裝並設定來用,但…一直搞不定。再加上它還提供了更多微軟方案中強大的 script 功能設定,要搞懂它比想像中的花時間。另外,在看程式碼時,發現它真正跟 Edge ReadAloud 整合的實作,是用 go 寫的,再利用 jni 的方式把 go 的功能引入。如此一來,如果我想改什麼的話,難度也就更高了些。
如果是在電腦上要執行的話,有一套 Python 的模組 edge-tts 可以使用。只要利用 pip install edge-tts 把它裝起來,就可以從終端機中呼叫。
最終,我決定要採用的是 Edge-TTS-Lib 。這是個去年 (2023) 出現在 Github 上的專案,沒半顆星,但是它除了 library 外,還提供了個範例程式,讓我可以直接測試是不是真的還可以用。
它的範例中,使用方式也很簡潔:
class MainActivity : AppCompatActivity() {
private lateinit var binding: ActivityMainBinding
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
binding= ActivityMainBinding.inflate(layoutInflater)
setContentView(binding.root)
binding.speak.setOnClickListener {
// 就這一行而已
TTS.getInstance().findHeadHook().speak("你好啊")
}
}
}
初步整合
這個函式庫很小,只有幾個程式檔,其中好幾個還是單純的資料格式宣告。所以,與其在 build.gradle 中引入這函式庫,不如直接在 EinkBro 中建立一個 sub package,把這些檔案都搬進來。
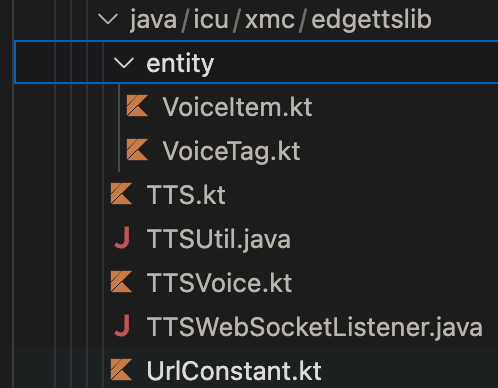 Code Hierarchy for Edge-TTS-Lib
Code Hierarchy for Edge-TTS-Lib
後來也證明這是個明智的決定,因為我把相關的程式碼都做了縮減,改寫和重構,最終主要的程式碼只剩下一個檔案而已。
 tts related codes in EinkBro
tts related codes in EinkBro
調整、縮減和重構
既然將它納入 EinkBro,它就不再是個 generic 的函式庫,要考慮到各種設定或客製化的可能性,我可以把它改造成 EinkBro 需要的形狀。
首先,TTS-Lib 的原始實作是在收到來自 MS Edge ReadAloud API 來的語音資料後,會先將內容寫到暫存檔中,再把暫存檔傳給 MediaPlayer 播放。以其他應用來說,這種直接把播放邏輯也處理掉的方式應該是比較討喜的。使用的人就不用再自己實作播放的細節。
不過,我想像中 EinkBro 提供的功能是:可以讓使用者中斷或暫停目前播放的內容;而且我也希望可以做點 pre-fetch,而不是播完一段文字後,才再去呼叫一次 API,等它回傳、寫檔後才又由 MediaPlayer 播放。
為此,最先做的改造是:
- 把程式碼中,語音文件播放的功能拿掉。這會留待 EinkBro 的 ViewModel 中,針對使用場景去處理。
- 不再將收到的語音內容寫入暫存檔。這件事有點多此一舉。MediaPlayer 是可以從 InputStream 中讀取資料,直接播放的,沒有必要進行多餘的 IO 讀寫。上圖中的 ByteArrayMediaSource 就是為了做這件事而撰寫的。
- 將原先 TTS.kt 的一堆 getter / setter,初始工作拔掉,只留下 EinkBro 會使用到的設定。
- 拿掉 TTSUtil.java, TTSVoice.kt, TTSWebSocketListener.java, UrlConstant.kt 這些文件的內容在經過縮減後都很小,其實可以直接宣告或實作在 TTS.kt 中就行。
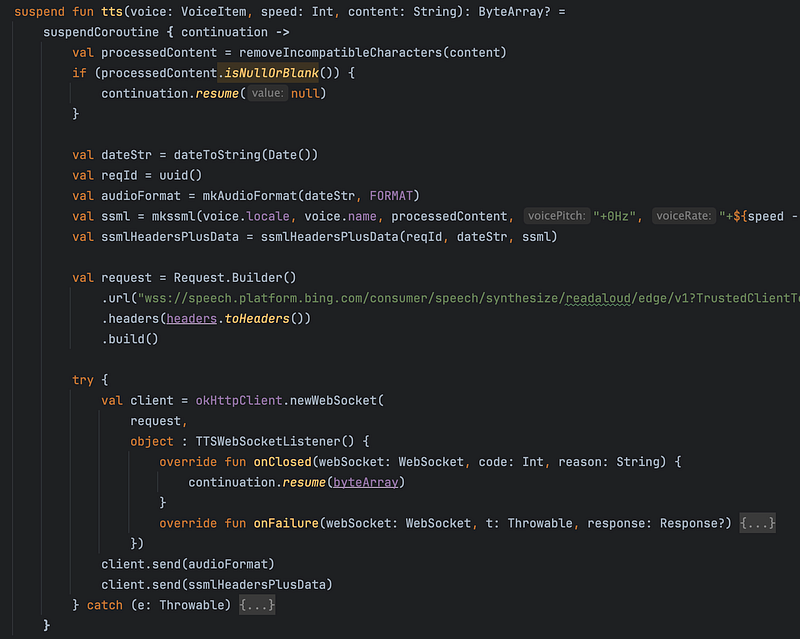
調整完的 TTS.kt 中,原先用來呼叫 MS API 並播放語音的函式,變成了這個樣子:可以根據帶入的語音角色、速度、和文字,輸出從 API 端取得的 ByteArray。
整合到既有的 ViewModel 中
播放邏輯
原先的 EinkBro 已經支援系統內建的語音功能,也可以使用 OpenAI 提供的 tts API。相關的設定有的在設定畫面裡,有的在朗讀按鈕點擊後的對話框裡。
為了再加入新成員,先重新調整了一下對話框的功能如下,讓使用者可以在這裡就決定想用哪個方式朗讀網頁內容。根據不同的方式,會呈現不同的設定讓使用者調整。
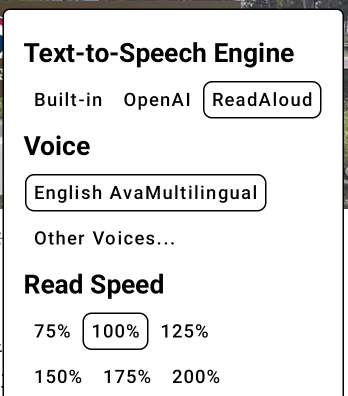
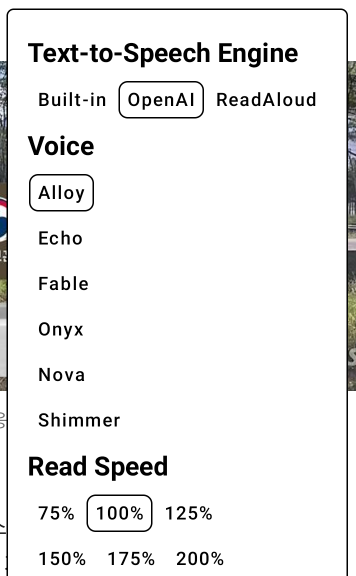
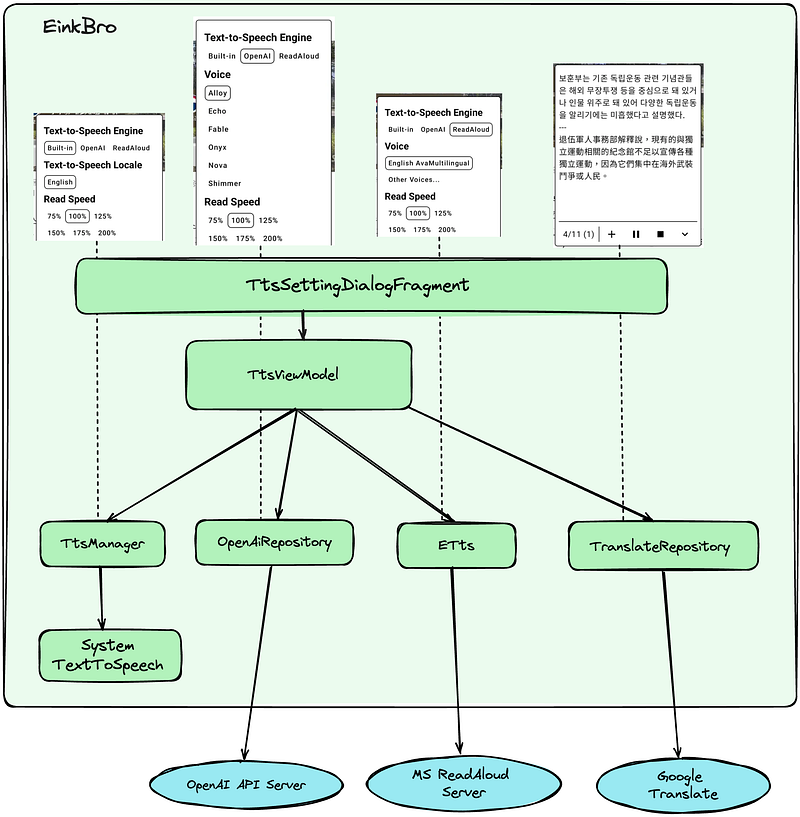
 目前支援的三種語音模式:MS ReadAloud, OpenAI, Built-in
目前支援的三種語音模式:MS ReadAloud, OpenAI, Built-in
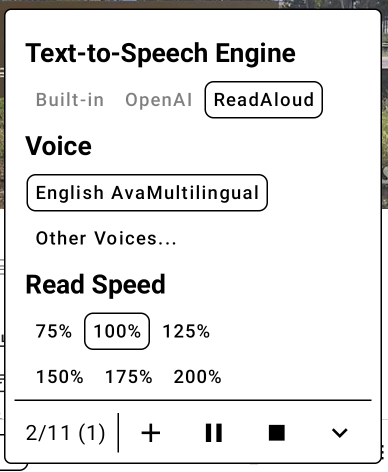
有了播放設定後,再來是播放狀態的呈現和控制。為了要讓這強大的語音效果能一次多唸幾篇文章,在 ViewModel 中加了一個 articlesToBeRead 的列表,存放著使用者塞了多少文章內容進來,準備在目前文章唸完後,接著往下唸。畫面左下角的文字進度顯示是:
目前朗讀中的區塊 / 目前文章總共有多少區塊 (有多少文章待讀)
 ,
,
為什麼要用區塊而不是用句子數量或是語音長度來當進度呢?
如果想用語音長度來當進度的話,前提是所有內容都已經轉成了文字才會知道總長。這在 EinkBro 中是不符合使用體驗的。一篇文章要全都轉成語音,勢必要花不少時間,所以,目前的作法是把兩三句句子,湊成一定長度後,就送去打 API,期待 OpenAI 或 MS ReadAloud 可以快速地反回語音內容,先開始朗讀;接著,趁使用者在聽當前區塊時,趕快再在背景多抓一兩個區塊的語音回來。
只能偷抓一兩個區塊備用,多了也不行。為什麼呢?因為打 OpenAI tts API 是要錢的。總不行使用者只聽了一句,按了停止,結果 EinkBro 在背後偷偷把整篇文章的語音都抓了回來吧。
下面的邏輯是用來處理 OpenAI tts API 和 MS ReadAloud 的作法。在切好區塊後,利用 Channel 的特性和一個 Semaphore 來控制有多少區塊被送去 API 取回語音。
第 19 行的 send() 會被第 34 行的 playAudioByteArray() 給阻擋住。唯有語音播放完成後,語音發送端才能再把資料餵進 Channel 中。
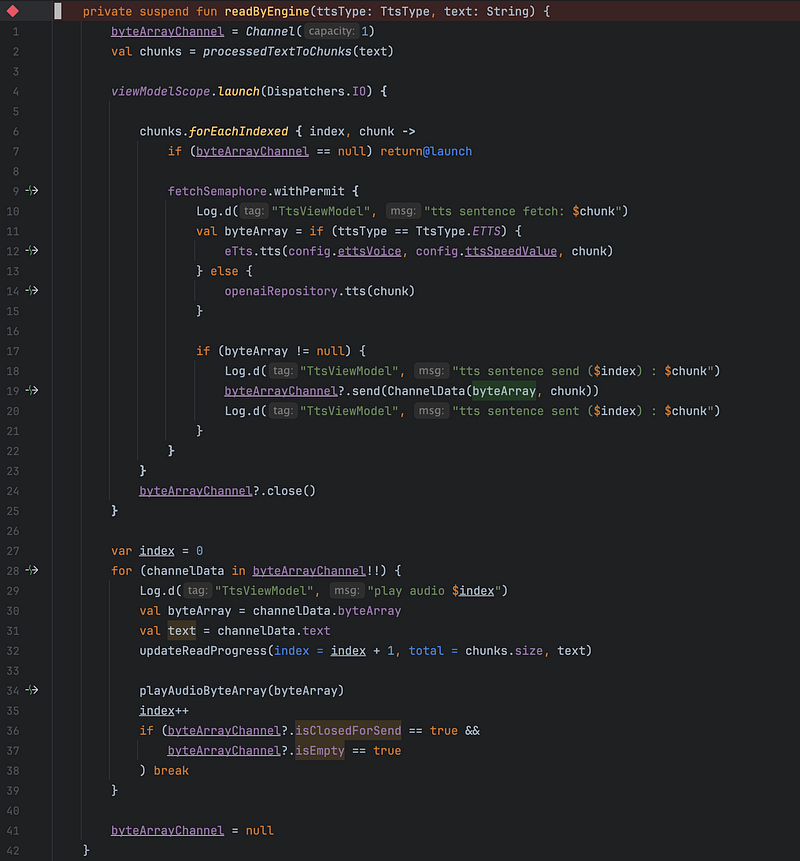
上圖中的 processedTextToChunks () 實作如下:在分區塊大小時,必須先考慮到語言的差異。如果是歐美語系的話,希望能用 word 為單位,計算內容的多寡。而中文、日文、韓文的話,則希望是以字為單位,計算內容多寡。
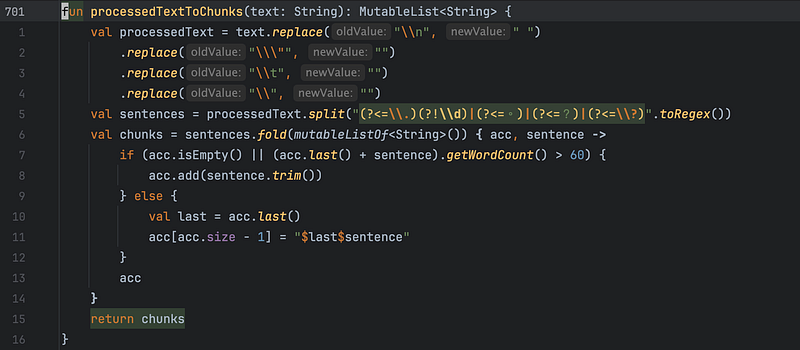
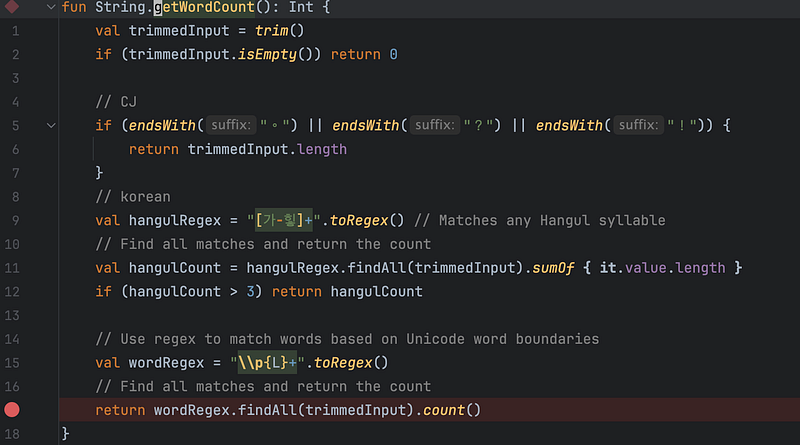
中文和日文大多會用。為句子結尾,所以不難處理。而韓文,因為使用的句子結尾符號跟英文一樣是 . ,所以只能另外處理。這邊使用了另一個 getWordCount() 的實作來處理這細節:
播放狀態
原先 ViewModel 中的播放狀態很陽春,只有一個 Boolean 值在記錄目前是否有在朗讀中,用來顯示工具列和功能選單上按鈕的狀態。
現在,為了要能呈現準備中,播放中,暫停,以及停止後的各種狀態,建立了 enum class 來更精準地記錄各種狀態;然後,再讓對話框的 compose 依照當前狀態呈現對應的按鈕和功能。
enum class TtsReadingState {
PREPARING, PLAYING, PAUSED, IDLE
}
呈現朗讀的內容,及其翻譯結果
最終,我最想要的功能加了上來。MS Edge 瀏覽器上,如果讓它朗讀的話,它會進入 Reader Mode,並且隨著朗讀的進度,將文字內容標注起來。這樣子的作法很適合時時想看目前唸到哪的使用者;但是,對於一旦開始閱讀,就想一邊聽一邊看其他網頁的人來說,就被朗讀的畫面卡住了。另一個方式是從功能選單裡點擊大聲朗讀。雖然這樣子能將朗讀功能縮小成一個側邊的按鈕,卻無法加入其他想朗讀的文章。
為了良好的解決這問題,我在既有的 TTS 對話框中多了個功能:
只要點擊當前的進度資訊,就能將其他的設定元件隱藏,改成顯示目前在朗讀中的區塊。這麼一來,就不用執著於得要開啟原先的網頁才能知道在讀什麼內容。這對於聆聽母話的人來說,不是很重要的功能,因為不論看不看文字,都聽得懂在說什麼。
但是這對於語言學習的使用者來說,就至關重要。加上文字的呈現通常可以更容易理解朗讀的內容。
那…如果文字還是看不懂時怎麼辦呢?關於這一點也考慮到了:只要點擊文字內容,它就會顯示翻譯後的結果。這麼一來,即使聽力不是很好的使用者也可以透過文字和翻譯來學習聽到的內容。


相關連結
目前這些實作大多在 v12.0.0 和後續的 30, 40 支 commit 中。因為更新的方式有點片段和局部性,所以無法直接提供完整的程式碼連結。