在前一篇提到,可以利用 epublib 將網頁內容儲存成 epub 檔案,便於事後用其他的閱讀軟體中操作。不過,由於當時對於 epublib 函式庫不夠熟悉,只能將網頁中的文字部分儲存下來。今天要來說說,怎麼實作儲存圖片的方式,和使用者體驗改善。
如何實作儲存圖片
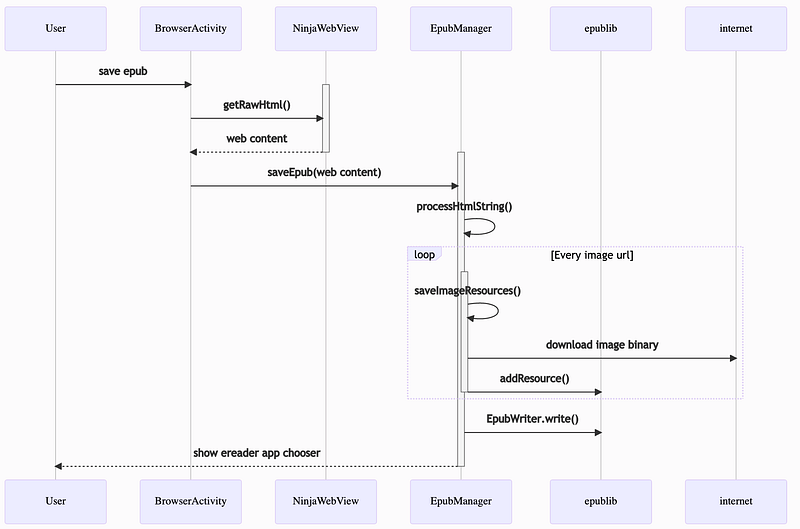 Sequence Diagram
Sequence Diagram
在一般網頁內容中,圖片的網址是來自於網路上的某個路徑;當要將網頁內容存進 epub 時,這些圖片的來源必須改成一個參考值 (reference),然後在 epublib 中加入新的 Resource,把參考值和實際的 image binary content 連結在一起。所以,在儲存 epub 時,先用 jsoup 將網頁內容中的所有圖片的元件找出來,把它們的 src 改成特定的參考值;將這些參考值和真正的網址存進一個 map。然後呼叫 saveImageResources() 函式,把 map 中的所有圖片都下載下來,一一加入 epub Book 中。
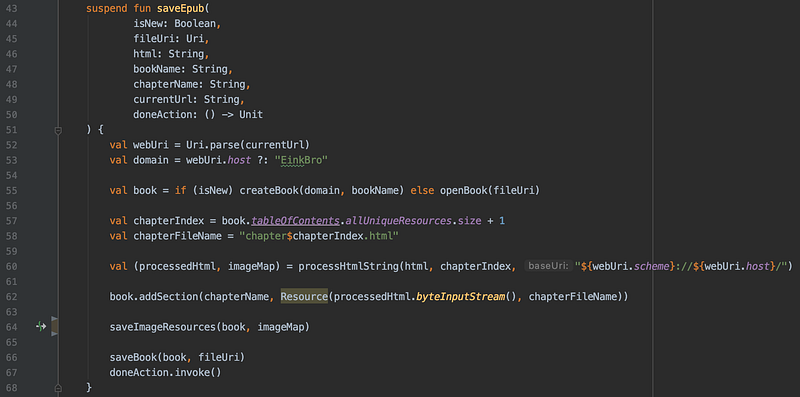 60 行:處理網頁圖片內容;64行:儲存圖片至 epub 中
60 行:處理網頁圖片內容;64行:儲存圖片至 epub 中
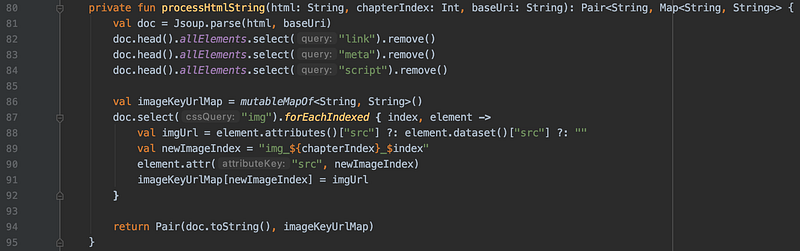 處理網頁內容,將 img 的 src 換成特定參考值,並傳出map
處理網頁內容,將 img 的 src 換成特定參考值,並傳出map
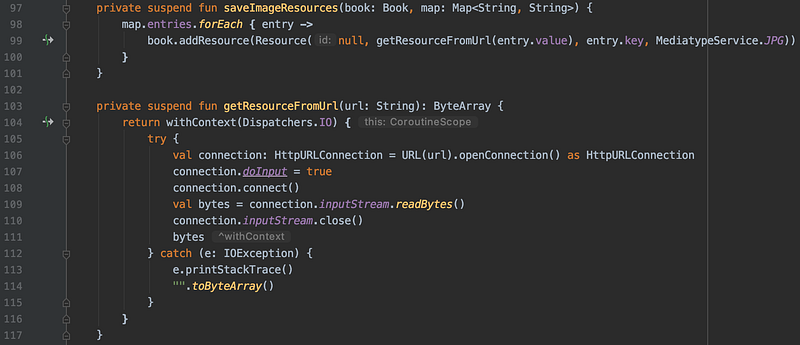 99行:利用 epublib 儲存圖片;103行:從網路下載圖片
99行:利用 epublib 儲存圖片;103行:從網路下載圖片
上圖中的 99 行很重要,最後面帶入的 MediatypeService.JPG 一定要加上才行。不然在儲存到既有的 epub 時,會發生之前儲存好的圖片會消失不見。應該是因為在讀取既有的 epub 時,因為事前沒有給予正確的 mimeType 值,造成它無法順利地讀取出來,也就無法在第二次寫入時,再完整地寫進同個 epub 文件中。
下載圖片的小枚角
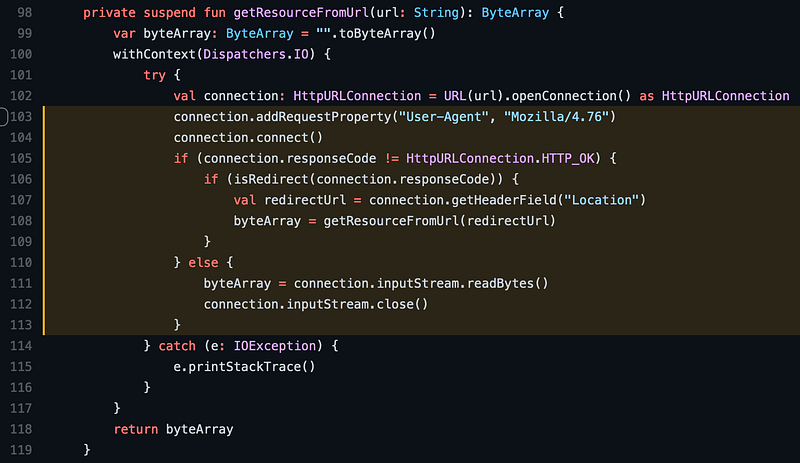
上圖中的 getResourceFromUrl 看似簡單,但有時候卻會發生,明明 browser 中看得到圖片,可是轉到 epub 時,這些圖片依然沒有被正常的寫入。後來再追查了一下,有兩個地方可能會出錯。一個是需要加入 User-Agent 的 header,避免有些網站會擋掉沒有帶正常值的 request;第二點是有些圖片的網址可能原本是 http 型式,在 connection 回來時,可能不會立即回傳 binary data,而是回傳 responseCode 301 (redirect) ,要你重新去試一下 https 的網址拿資料。在這情況下如果沒有從 response header 中去抓出 Location 值重新要一次資料的話,就會無法正確地取回圖片。
以下是再更改過的抓圖實作。這次,應該真的處理了大部分 fail cases 了吧。
 handle redirect urls
handle redirect urls
自動抓取 Reader Mode 的網頁內容再儲存至 epub
大部分的網頁充滿著各式各樣的元件,不是很適合當成電子書閱讀。原先的版本需要使用者自己手動切換到 Reader Mode 後再儲存成 epub 文件才會有比較好的效果。這動作做多了,就覺得很煩。所以趁著 8.7.0 版本發布,把它改成自動的了。為了要達到這功能,必須修改原先寫好的 MozReadability.js 。
原先的 javasctipt 在最後段會透過 Readability 產生處理好的 article,再將 article 轉換成 html 塞到原本的網頁中。但是這步驟對於儲存 epub 來說是不必要的。
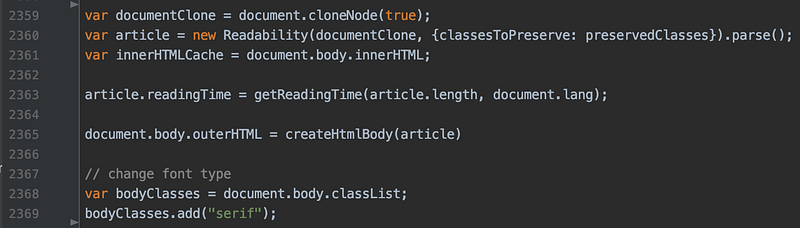 原先的內容
原先的內容
所以這一段被獨立了出來,只有在需要將現有網頁轉成 Reader Mode 時才注入。但是在儲存 epub 時,會利用下面的方式得到 Readability 處理好的 html 內容:
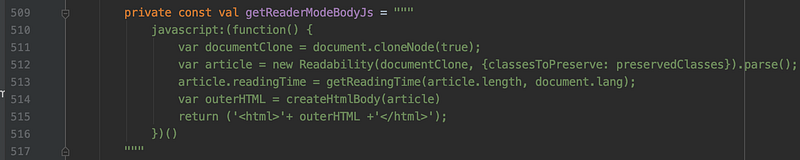 將轉好html 回傳至 native,進行後續處理
將轉好html 回傳至 native,進行後續處理